缓存穿透
问题描述
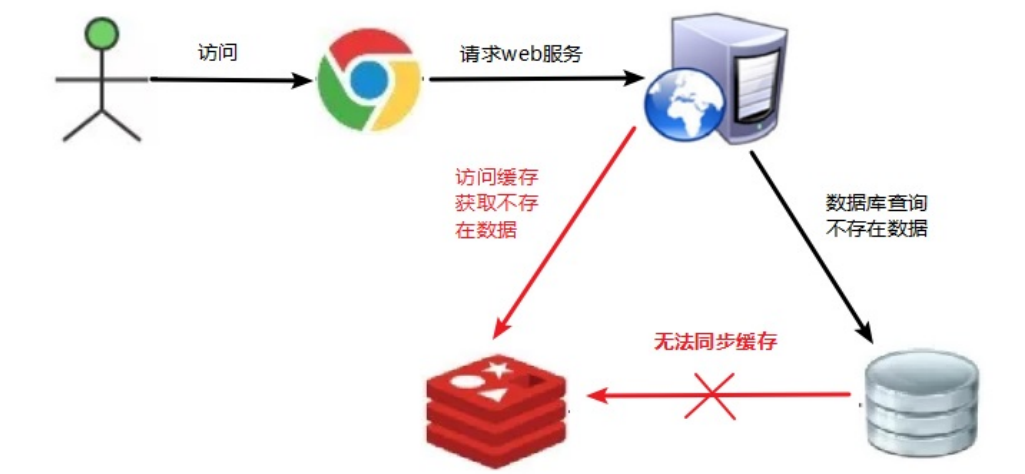
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去数据库查询。一些恶意的请求会故意大量查询不存在的key,就会对数据库造成很大的压力。这就叫做缓存穿透。
比如用一个不存在的商品id获取商品详情,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
伪代码演示:
@Autowired
RedisTemplate<String, Object> redisTemplate;
/**
* 模拟缓存穿透=》查询某个商品详情
*
* @param commodityId 商品ID
* @return
*/
@GetMapping("/penetrate")
public Object penetrate(String commodityId) {
// 1. 查询Redis,不存在此商品
System.out.println("开始查询缓存");
Object redisResult = redisTemplate.opsForValue().get(commodityId);
// 2. redis不存在查询数据库
if (redisResult == null) {
System.out.println("缓存不存在:开始查询数据库。。。");
System.out.println("数据库中实际也不存在数据");
// 方案1:对于数据库为null的值也进行缓存
redisTemplate.opsForValue().set(commodityId, "");
}
return redisResult;
}
解决方案
方案一:null值缓存
当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
// 方案1:对于数据库为null的值也进行缓存
redisTemplate.opsForValue().set(commodityId, "");
方案二:接口校验
在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
// 方案二:接口校验,商品ID长度小于10,直接返回null
if (commodityId.length() <= 10) {
return null;
}
方案三:访问限制
对于接口,可以实现限流访问,使用Sentinel或者Redis实现。对于同一IP或者用户,对当前商品ID查询进行限制访问,比如使用[IP+接口名+商品ID]为Key,10秒内限制访问总次数为3次。
对于接口,可以实现白名单访问限制,使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
对于接口,可以设置黑名单,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务。
此实现方案较为复杂,参考本系列具体文档。
方案四:布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
演示案例:
1、 添加pom;
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.1</version>
</dependency>
1、 伪代码;
@GetMapping("/penetrate")
public Object penetrate(String commodityId) {
// ### 方案四:布隆过滤器
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
config.useSingleServer().setPassword("123456");
// 构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("commodity");
// 初始化布隆过滤器:初始化大小、误差率
bloomFilter.tryInit(100000000L, 0.03);
// 将商品ID到布隆过滤器中
bloomFilter.add("a");
bloomFilter.add("b");
bloomFilter.add("c");
bloomFilter.add("d");
bloomFilter.add("e");
// 判断商品否存在
boolean result = bloomFilter.contains(commodityId);
System.out.println(commodityId + "是否存在:" + result);
if (result) {
// 存在查询缓存和数据库
System.out.println(commodityId + "存在:" + "开始查询数据....");
// 1. 查询Redis,不存在此商品
System.out.println("开始查询缓存");
Object redisResult = redisTemplate.opsForValue().get(commodityId);
// 2. redis不存在查询数据库
if (redisResult == null) {
System.out.println("缓存不存在:开始查询数据库。。。");
System.out.println("数据库中实际也不存在数据");
// 方案1:对于数据库为null的值也进行缓存
//redisTemplate.opsForValue().set(commodityId, "");
}
}
// 不存在直接返回空
return null;
// 方案二:接口校验,商品ID长度小于10,直接返回null
/* if (commodityId.length() <= 10) {
return null;
}*/
}
缓存击穿
问题描述
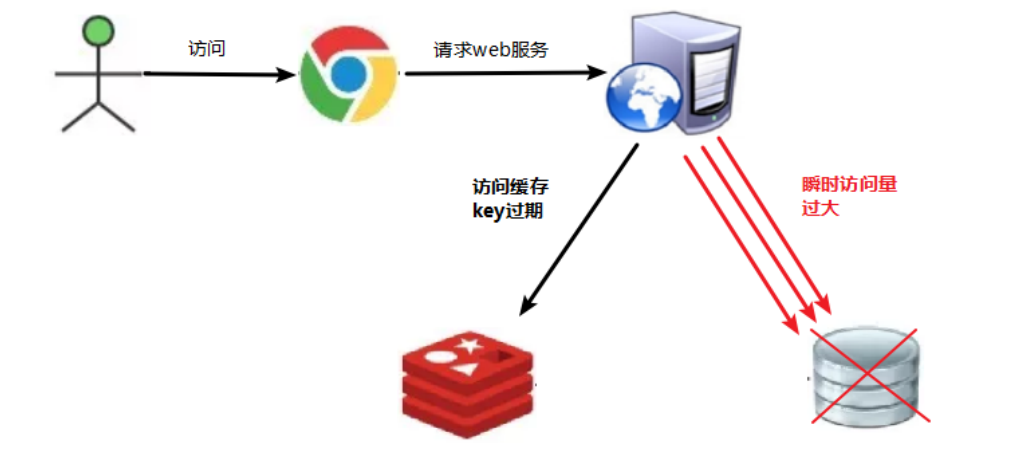
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
方案一:预先设置热门数据
在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长。
// 方案一:预先设置热门数据,设置过期时间为一天
redisTemplate.opsForValue().set(commodityId, "信息", 24, TimeUnit.HOURS);
方案二:添加锁
缓存失效的时候(判断拿出来的值为空),添加互斥锁。
@GetMapping("/breakdown")
public Object breakdown(String commodityId) {
// 1. 查询Redis,此时商品存在,但是已过期
System.out.println("开始查询缓存");
// 方案一:预先设置热门数据,设置过期时间为一天
// redisTemplate.opsForValue().set(commodityId, "信息", 24, TimeUnit.HOURS);
// 互斥锁
Object redisResult = redisTemplate.opsForValue().get(commodityId);
if (redisResult==null){
synchronized (Lock){
// 2. redis过期,大并发查询数据库
System.out.println("缓存过期:开始查询数据库。。。");
System.out.println("数据库查询到数据");
}
}
return redisResult;
}
缓存雪崩
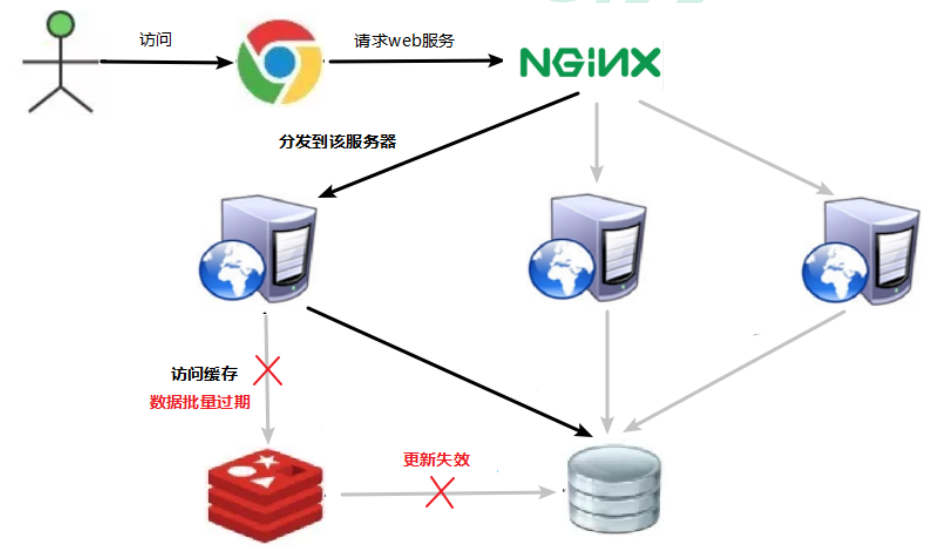
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
解决方案
方案一:构建多级缓存架构
nginx缓存 + redis缓存 +其他缓存(ehcache等)
方案二:使用锁或队列
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况。
方案三:设置过期标志更新缓存
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
方案四:将缓存失效时间分散开
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。